The Environs framework has now been updated with specifications for the PortalInstance and PortalInfo objects.
https://hcm-lab.de/environs/howtos/tutorial-api-calls-and-notifications/portalinstance-objects/

The Environs framework has now been updated with specifications for the PortalInstance and PortalInfo objects.
https://hcm-lab.de/environs/howtos/tutorial-api-calls-and-notifications/portalinstance-objects/
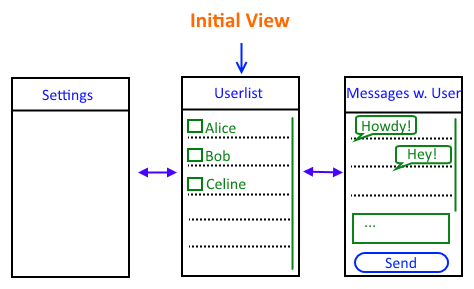
The first part of a tutorial on howto conceptualize, design, and realize a simple chat application using the Environs framework has been written and published: -> ChatApp Tutorial
This may only of interesest to you if you’re a (n interaction) designer.. However, … first part done… :D
As of today, the project page of Environs got online and is well prepared for the EICS conference in Rome.
Environs was developed so as to enable research for my PhD thesis within. It enables simple and efficient implementations of distributed applications and user interfaces for multi display environments. Have a look at the project page http://hcm-lab.de/environs

As a sidenote to the recent post, the therein presented kernel is already superfast, but guess what :-)
There are ways to make it even faster by virtue of memory access optimizations. Let’s consider the memory access of U and V plane. They both access the same bits within the same dimension, thus can be consolidated into the same work item to access the memory only once (global memory access is the slowest memory access type).
Futhermore, “flattening” the work-group from 2D to 1D enables faster sequential memory access instead of the presented 2D access, hence benefit much better from prefetching and probably help avoiding bank conflicts…
So far for optimizations.. If there is demand on an appropriate kernel, then drop me an email..
Just submitted a post at stackoverflow which would also have a nice place here, so.. here we go :-)
It was concerning the topic how to convert ARGB to YUV using the GPU. Some time ago I’ve developed and used the following OpenCL kernel to convert ARGB (typical windows bitmap pixel layout) to the y-plane (full sized), u/v-half-plane (quarter sized) memory layout as input for libx264 encoding.
__kernel void ARGB2YUV (
__global unsigned int * sourceImage,
__global unsigned int * destImage,
unsigned int srcHeight,
unsigned int srcWidth,
unsigned int yuvStride // must be srcWidth/4 since we pack 4 pixels into 1 Y-unit (with 4 y-pixels)
)
{
int i;
unsigned int RGBs [ 4 ];
unsigned int posSrc, RGB, Value4 = 0, Value, yuvStrideHalf, srcHeightHalf, yPlaneOffset, posOffset;
unsigned char red, green, blue;
unsigned int posX = get_global_id(0);
unsigned int posY = get_global_id(1);
if ( posX < yuvStride ) {
// Y plane - pack 4 y's within each work item
if ( posY >= srcHeight )
return;
posSrc = (posY * srcWidth) + (posX * 4);
RGBs [ 0 ] = sourceImage [ posSrc ];
RGBs [ 1 ] = sourceImage [ posSrc + 1 ];
RGBs [ 2 ] = sourceImage [ posSrc + 2 ];
RGBs [ 3 ] = sourceImage [ posSrc + 3 ];
for ( i=0; i<4; i++ ) {
RGB = RGBs [ i ]; blue = RGB & 0xff; green = (RGB >> 8) & 0xff; red = (RGB >> 16) & 0xff;
Value = ( ( 66 * red + 129 * green + 25 * blue ) >> 8 ) + 16;
Value4 |= (Value << (i * 8));
}
destImage [ (posY * yuvStride) + posX ] = Value4;
return;
}
posX -= yuvStride; yuvStrideHalf = yuvStride >> 1;
// U plane - pack 4 u's within each work item
if ( posX <= yuvStrideHalf )
return;
srcHeightHalf = srcHeight >> 1;
if ( posY < srcHeightHalf ) {
posSrc = ((posY * 2) * srcWidth) + (posX * 8);
RGBs [ 0 ] = sourceImage [ posSrc ];
RGBs [ 1 ] = sourceImage [ posSrc + 2 ];
RGBs [ 2 ] = sourceImage [ posSrc + 4 ];
RGBs [ 3 ] = sourceImage [ posSrc + 6 ];
for ( i=0; i<4; i++ ) {
RGB = RGBs [ i ];
blue = RGB & 0xff; green = (RGB >> 8) & 0xff; red = (RGB >> 16) & 0xff;
Value = ( ( -38 * red + -74 * green + 112 * blue ) >> 8 ) + 128;
Value4 |= (Value << (i * 8));
}
yPlaneOffset = yuvStride * srcHeight;
posOffset = (posY * yuvStrideHalf) + posX;
destImage [ yPlaneOffset + posOffset ] = Value4;
return;
}
posY -= srcHeightHalf;
if ( posY >= srcHeightHalf )
return;
// V plane - pack 4 v's within each work item
posSrc = ((posY * 2) * srcWidth) + (posX * 8);
RGBs [ 0 ] = sourceImage [ posSrc ];
RGBs [ 1 ] = sourceImage [ posSrc + 2 ];
RGBs [ 2 ] = sourceImage [ posSrc + 4 ];
RGBs [ 3 ] = sourceImage [ posSrc + 6 ];
for ( i=0; i<4; i++ ) {
RGB = RGBs [ i ];
blue = RGB & 0xff; green = (RGB >> 8) & 0xff; red = (RGB >> 16) & 0xff;
Value = ( ( 112 * red + -94 * green + -18 * blue ) >> 8 ) + 128;
Value4 |= (Value << (i * 8));
}
yPlaneOffset = yuvStride * srcHeight;
posOffset = (posY * yuvStrideHalf) + posX;
destImage [ yPlaneOffset + (yPlaneOffset >> 2) + posOffset ] = Value4;
return;
}
This code performs only global 32-bit memory access while 8-bit processing happens within each work item.
Oh.. and the proper code to invoke the kernel
unsigned int width = 1024;
unsigned int height = 768;
unsigned int frameSize = width * height;
const unsigned int argbSize = frameSize * 4; // ARGB pixels
const unsigned int yuvSize = frameSize + (frameSize >> 1); // Y,U,V planes
const unsigned int yuvStride = width >> 2; // since we pack 4 RGBs into "one" YYYY
// Allocates ARGB buffer
ocl_rgb_buffer = clCreateBuffer ( context, CL_MEM_READ_WRITE, argbSize, 0, &error );
// ... error handling ...
ocl_yuv_buffer = clCreateBuffer ( context, CL_MEM_READ_WRITE, yuvSize, 0, &error );
// ... error handling ...
error = clSetKernelArg ( kernel, 0, sizeof(cl_mem), &ocl_rgb_buffer );
error |= clSetKernelArg ( kernel, 1, sizeof(cl_mem), &ocl_yuv_buffer );
error |= clSetKernelArg ( kernel, 2, sizeof(unsigned int), &height);
error |= clSetKernelArg ( kernel, 3, sizeof(unsigned int), &width);
error |= clSetKernelArg ( kernel, 4, sizeof(unsigned int), &yuvStride);
// ... error handling ...
const size_t local_ws[] = { 16, 32 };
const size_t global_ws[] = { yuvStride + (yuvStride>>1), height };
error = clEnqueueNDRangeKernel ( queue, kernel, 2, NULL, global_ws, local_ws, 0, NULL, NULL );
// ... error handling ...
Note: have a look at the work item calculations. Some additional code needs to be added (e.g. using mod so as to add sufficient spare items) to make sure that work item sizes fit to local work sizes.